Kubernetes Controllers: Deployment, StatefulSet, and ReplicaSet Explained

Kubernetes gives you three primary workload controllers: ReplicaSet, Deployment, and StatefulSet. They look similar on the surface — they all manage pods — but they solve fundamentally different problems. Picking the wrong one leads to either unnecessary complexity or broken guarantees.
This post walks through each controller, what makes it tick, and how to decide which one belongs in your manifest.
The Foundation: The Controller Pattern
Before looking at individual controllers, it helps to understand what they all share: the reconciliation loop.
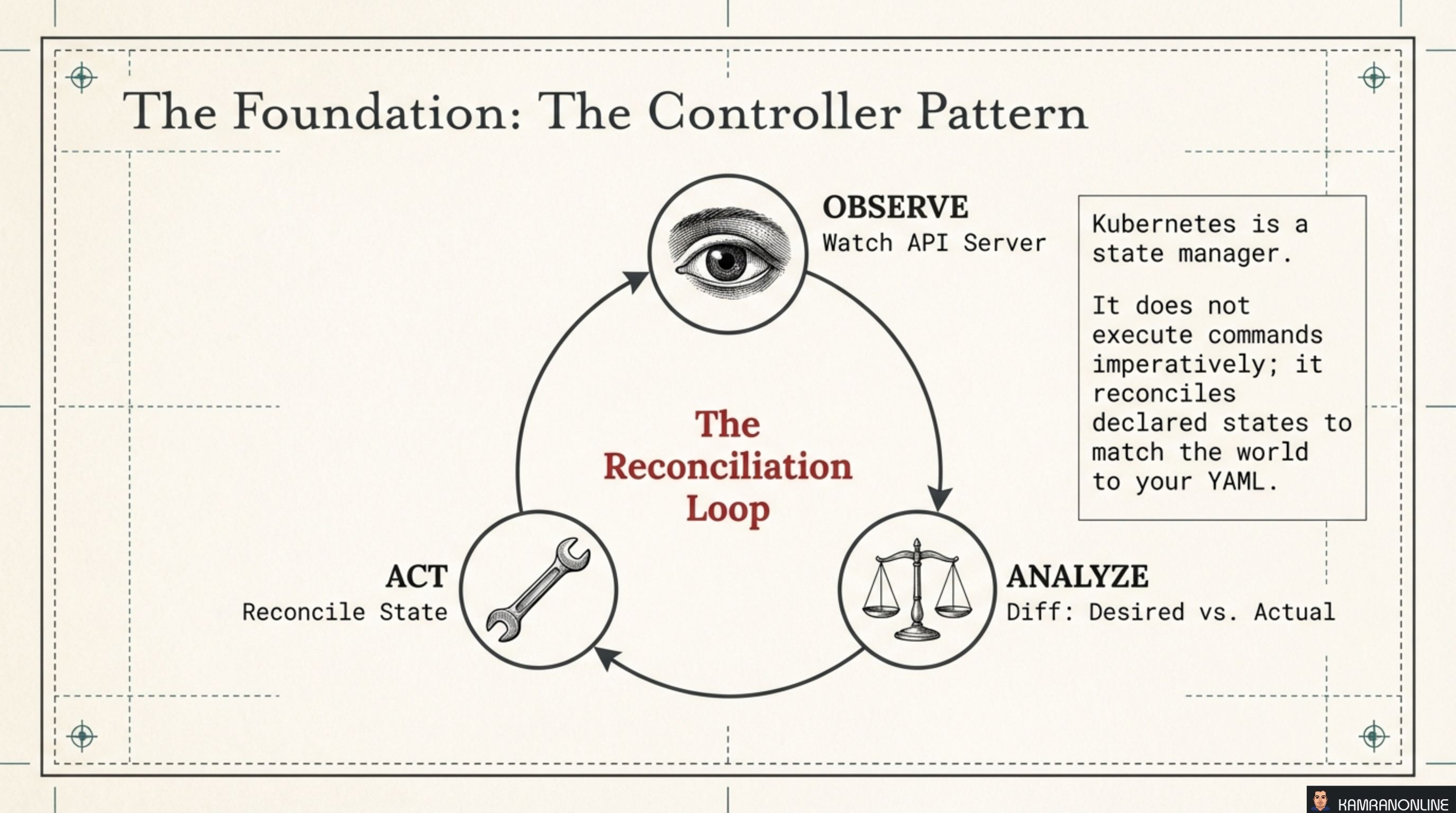
Kubernetes is not an imperative executor. You don’t tell it “start three pods.” You declare “I want three pods running” and a controller continuously works to make reality match that declaration. The loop has three steps:
- Observe — watch the API server for changes to resources
- Analyze — diff the desired state (your YAML) against the actual state (what’s running)
- Act — reconcile: create, update, or delete resources to close the gap
This is why Kubernetes is resilient. If a pod dies, no human intervenes — the controller detects the drift and acts. If a node goes down, controllers on other nodes pick up the work. The system is always converging toward your declared intent.
ReplicaSet: The Sustainer
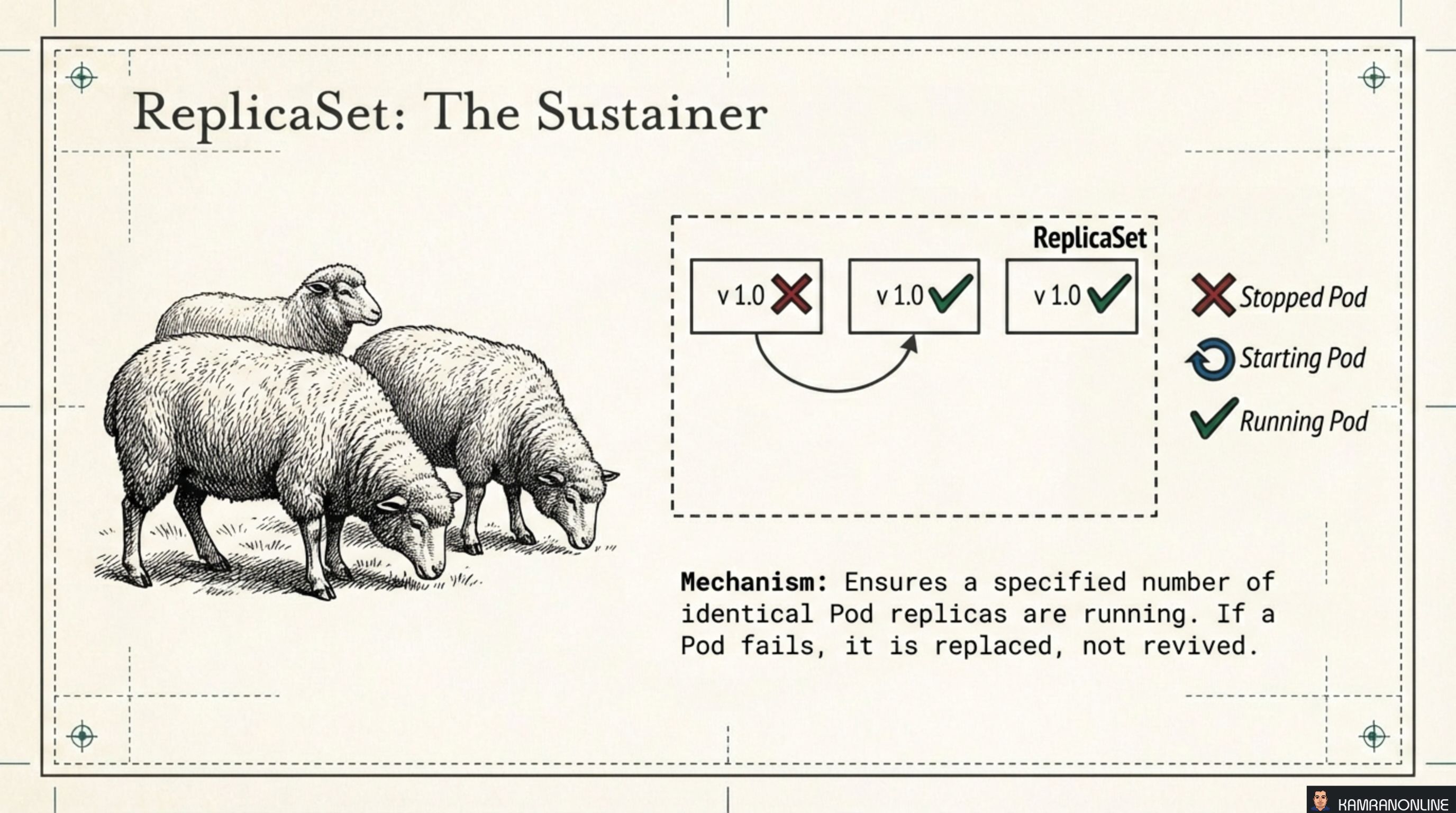
A ReplicaSet has one job: ensure exactly N identical pods are running at all times. When a pod fails, the ReplicaSet replaces it — it doesn’t try to revive the failed instance, it creates a fresh one.
The sheep analogy from the illustration is apt. All pods are identical, interchangeable. If one is lost, you get a new one. No attachment, no identity.
Deep Dive: ReplicaSet

| Dimension | ReplicaSet behaviour |
|---|---|
| Goal | High availability — guarantee “at least X” identical pods running |
| Identity | Weak / None — pods get random hash suffixes (e.g. app-5t43z); they are interchangeable cattle |
| Storage | Shared or ephemeral — all replicas write to the same shared PVC, or use no persistent storage at all |
| Scaling | Asynchronous and parallel — pods start in any order with no ordering guarantee on scale-up or scale-down |
In practice: You rarely write a bare ReplicaSet. Deployments manage ReplicaSets for you and add update and rollback semantics on top. Use a ReplicaSet directly only when building a custom operator that needs fine-grained control over replica management.
Deployment: The Manager
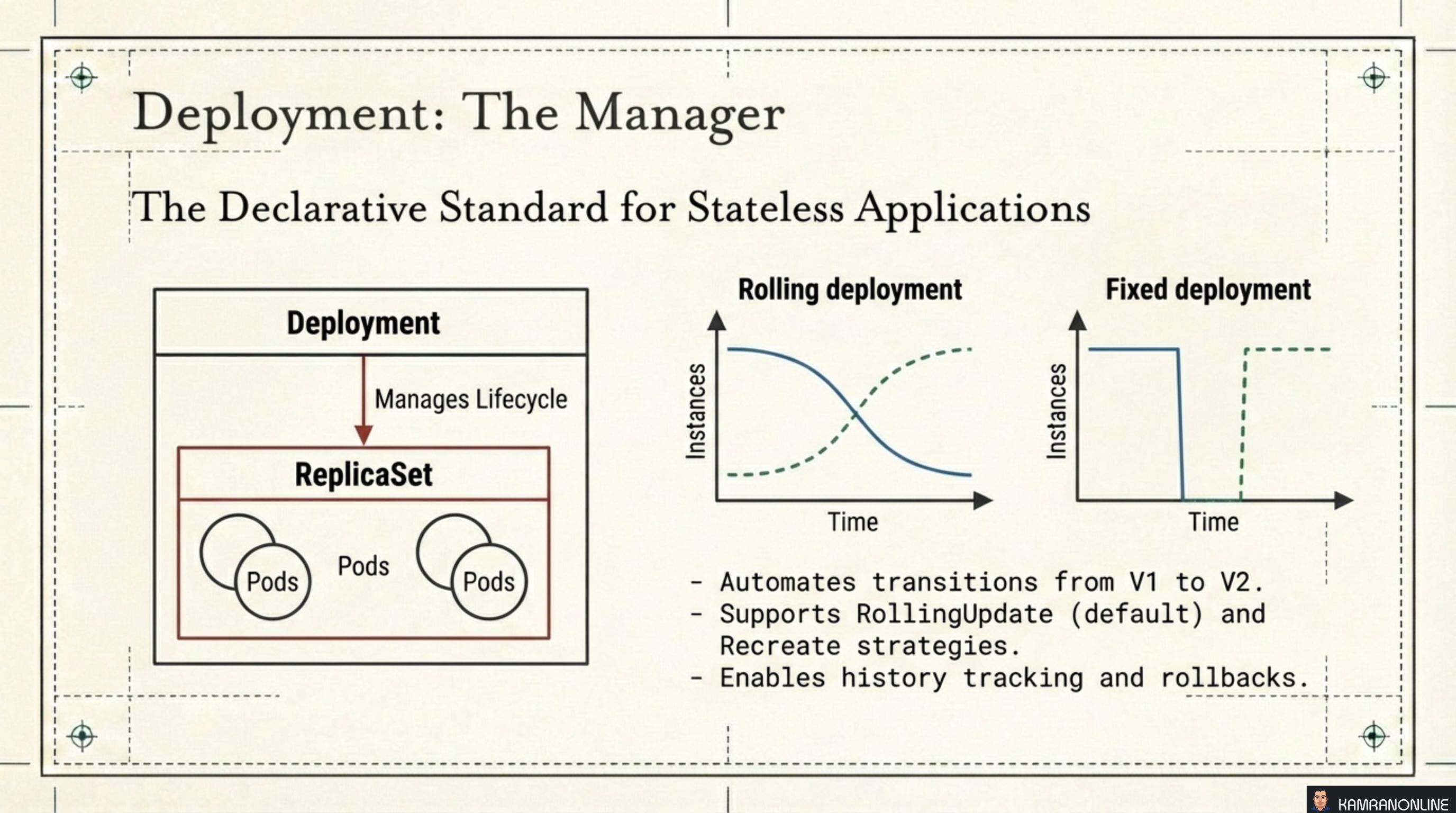
A Deployment sits one level above a ReplicaSet. It manages the ReplicaSet lifecycle, automating the transition from one version of your application to another. This is the declarative standard for stateless applications.
Two update strategies are available:
- RollingUpdate (default) — gradually replaces old pods with new ones, keeping some instances available throughout. Zero downtime.
- Recreate — terminates all old pods before creating any new ones. Causes a brief outage, but guarantees no two versions run concurrently. Useful when your app cannot tolerate mixed versions.
Deployments also track revision history, enabling one-command rollbacks:
kubectl rollout undo deployment/my-app
kubectl rollout undo deployment/my-app --to-revision=3Deep Dive: Deployment
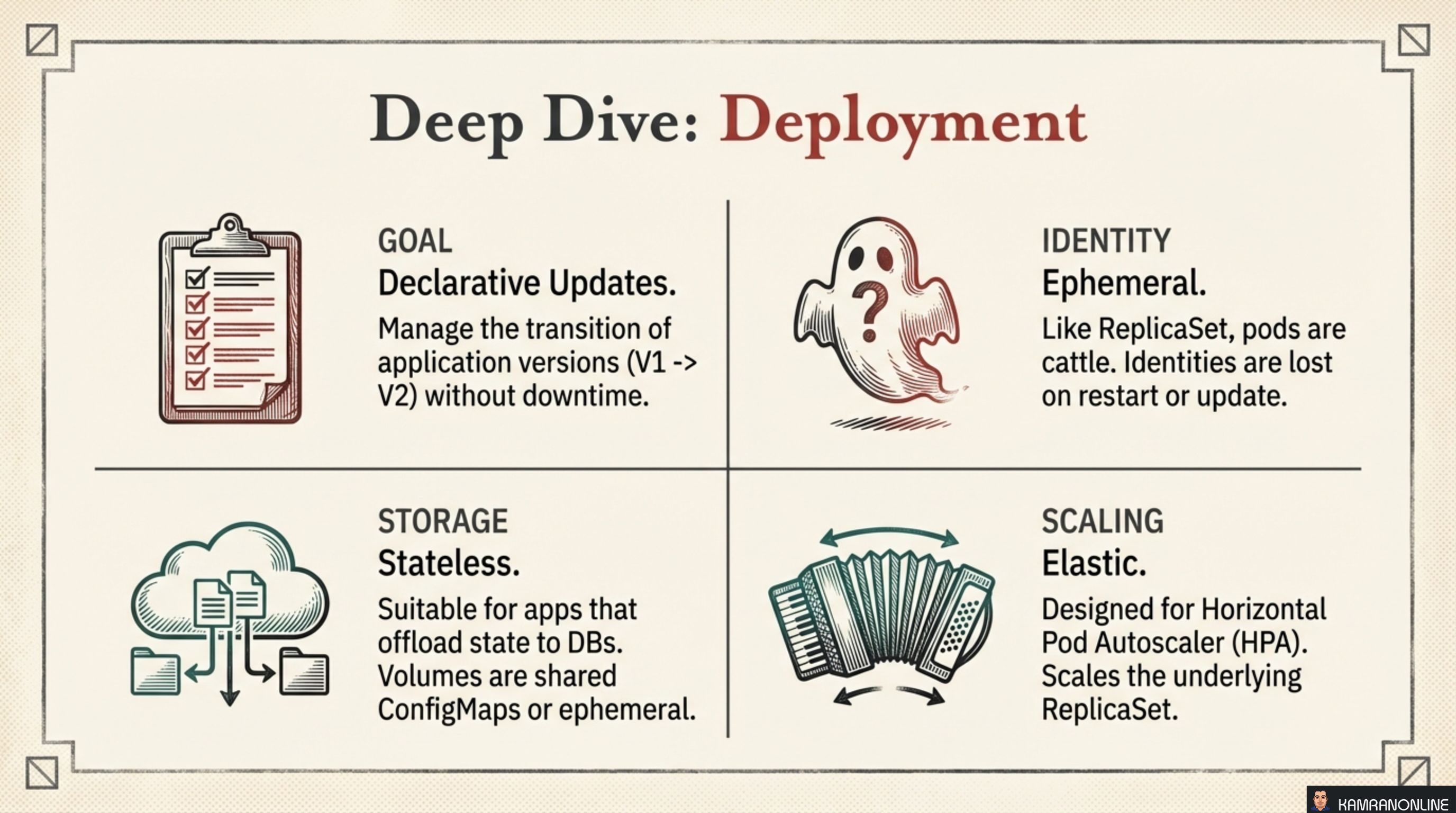
| Dimension | Deployment behaviour |
|---|---|
| Goal | Declarative updates — manage the transition from V1 to V2 without downtime |
| Identity | Ephemeral — pods are cattle; identities are lost on restart or update |
| Storage | Stateless — suitable for apps that offload state to external databases; volumes are shared ConfigMaps or ephemeral |
| Scaling | Elastic — designed for HPA (Horizontal Pod Autoscaler); scales the underlying ReplicaSet |
Visualising the Rolling Update Lifecycle
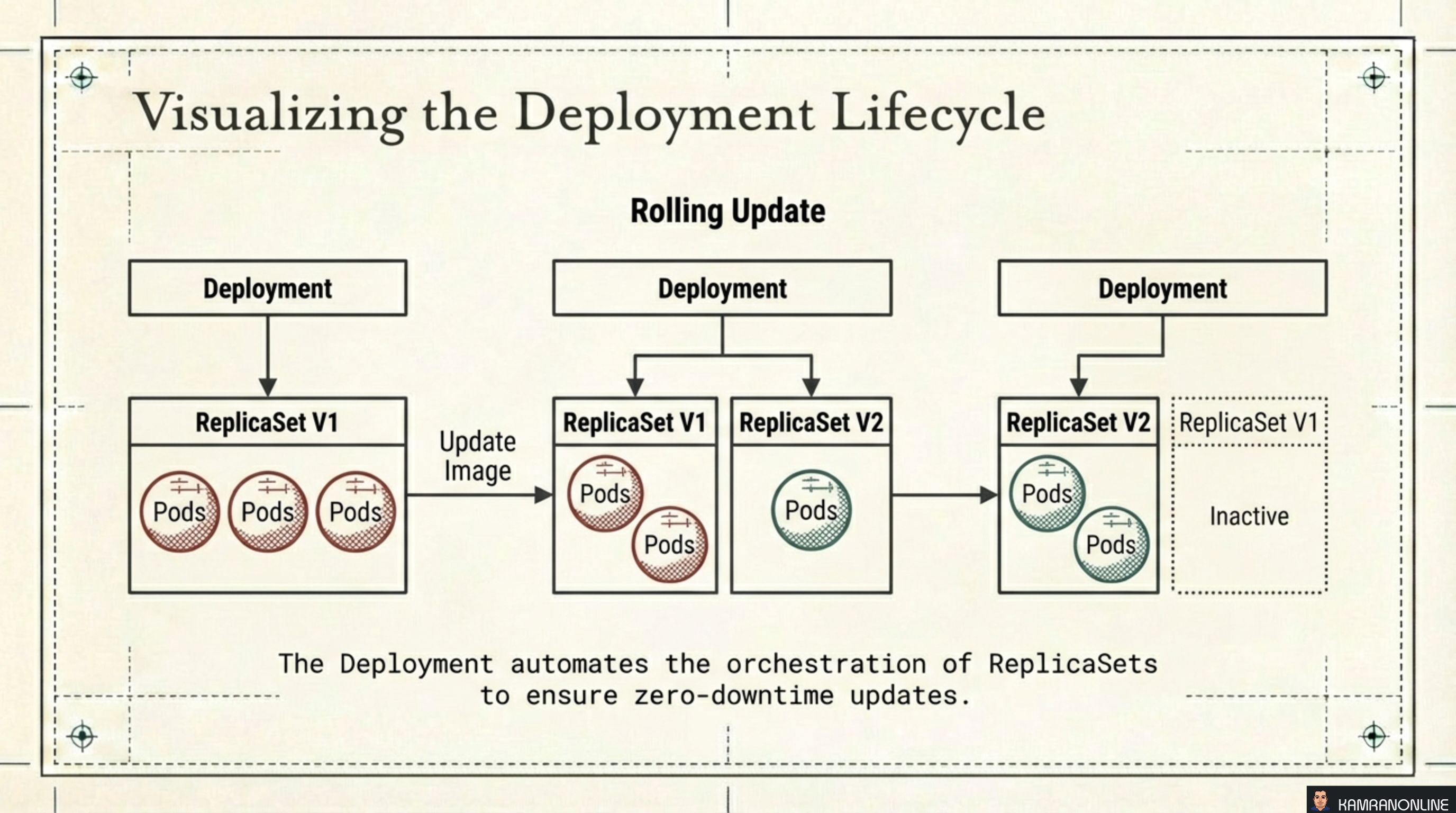
The diagram shows what actually happens during a rolling update:
- Start: Deployment owns ReplicaSet V1 (3 pods running)
- Update triggered: A new ReplicaSet V2 is created; pods are gradually shifted from V1 to V2
- Complete: Deployment owns ReplicaSet V2 (3 pods running); ReplicaSet V1 is kept but scaled to zero — ready for an instant rollback if needed
This is why rollbacks are fast. The old ReplicaSet still exists with its pod template intact. Kubernetes just scales it back up.
StatefulSet: The Specialist

StatefulSet manages stateful applications where every instance is unique. The golden retriever illustration captures it well — unlike the interchangeable sheep of a ReplicaSet, each StatefulSet pod has its own name, its own network identity, and its own storage that follows it forever.
Primary guarantee: At-Most-One. Kubernetes will never allow two pods with the same identity to run simultaneously. This prioritises consistency and uniqueness over raw availability — the right trade-off for distributed data stores.
Typical use cases: Cassandra, MySQL, PostgreSQL, Kafka, ZooKeeper, etcd — any system where each node has a role in a cluster and must be reachable by a stable DNS name.
Deep Dive: StatefulSet
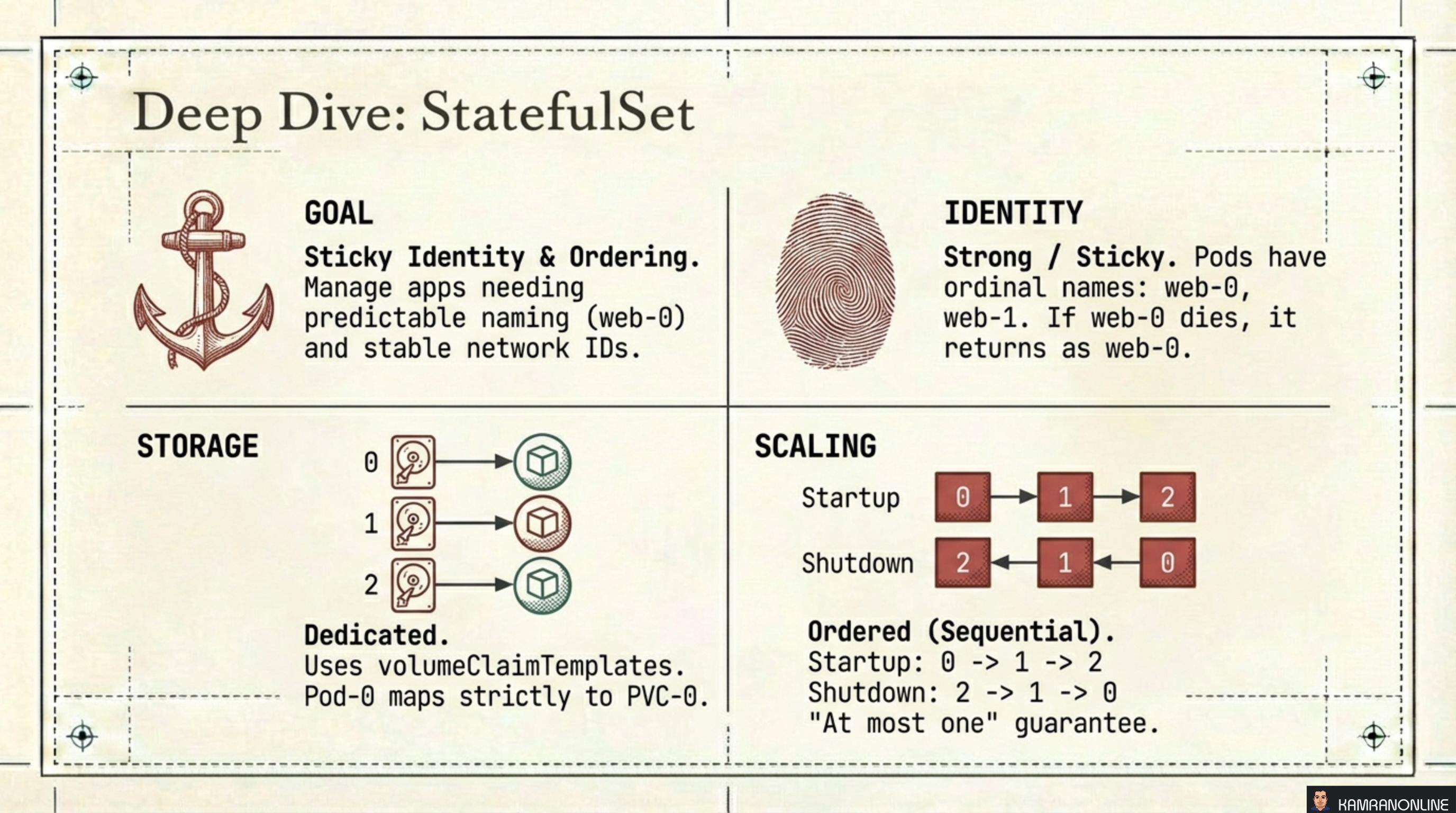
| Dimension | StatefulSet behaviour |
|---|---|
| Goal | Sticky identity and ordering — predictable names (web-0, web-1) and stable network IDs |
| Identity | Strong / Sticky — if web-0 dies, it comes back as web-0, not as web-7f3k2 |
| Storage | Dedicated per pod — volumeClaimTemplates create a separate PVC for each pod; pod-0 maps strictly to pvc-0 |
| Scaling | Sequential and ordered — startup: 0 → 1 → 2; shutdown: 2 → 1 → 0; “at most one” guarantee at all times |
The ordered scaling is critical for clustered databases. Cassandra’s bootstrapping process requires each node to join the ring sequentially. If Kubernetes spun up all replicas in parallel, the cluster would be corrupted.
Architecture Comparison: Stateless vs. Stateful
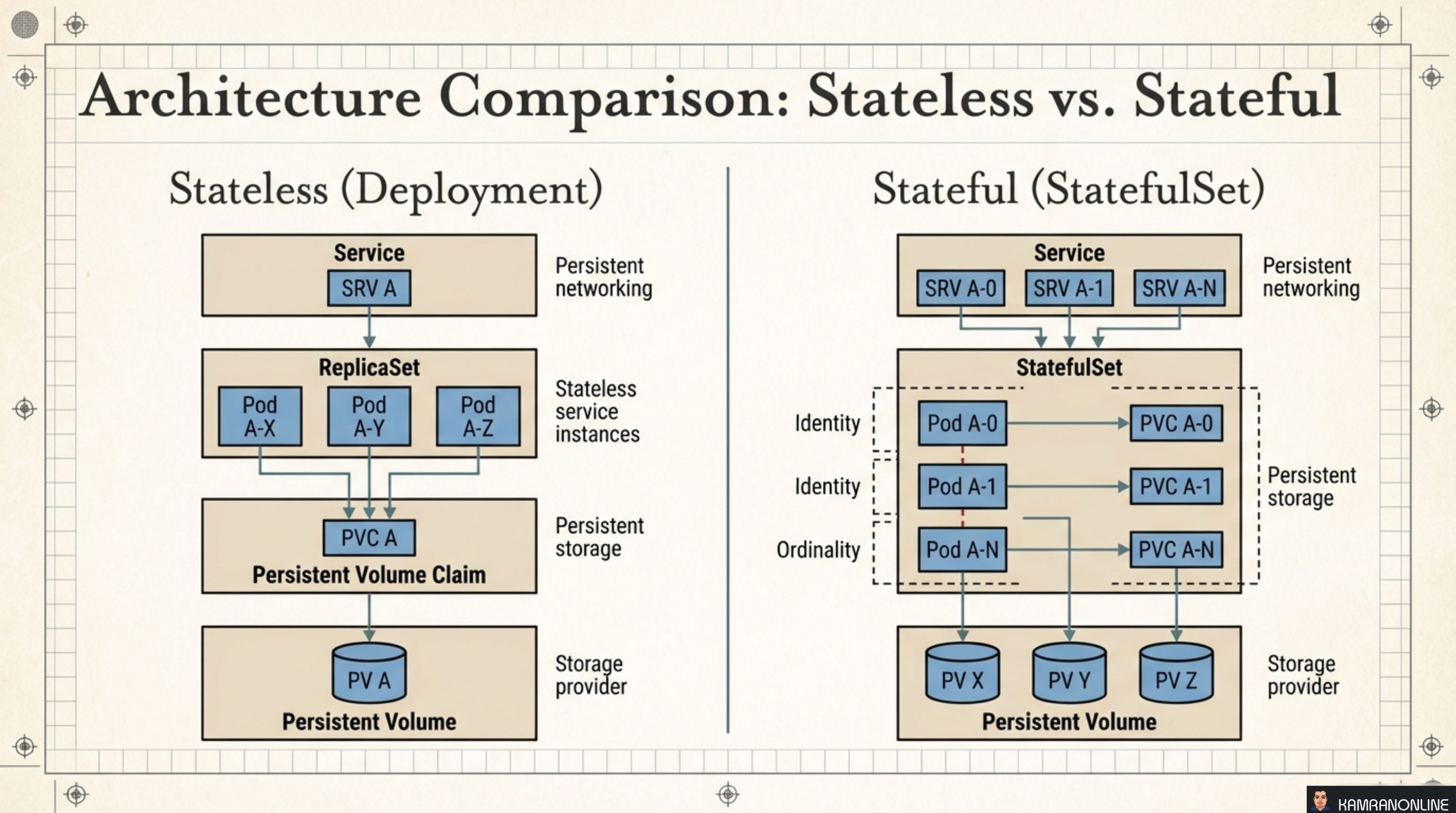
The side-by-side diagram makes the structural difference concrete:
Stateless (Deployment)
- A single Service routes to any pod — pods are anonymous
- All pods share the same PVC (or use no persistent storage)
- Pod names are random; losing one doesn’t matter
Stateful (StatefulSet)
- Each pod gets its own Headless Service DNS entry (
pod-0.service,pod-1.service) - Each pod owns its own PVC, mapped by ordinal
- Pod names are fixed; the cluster peers need to know exactly who they’re talking to
The Comparison Matrix
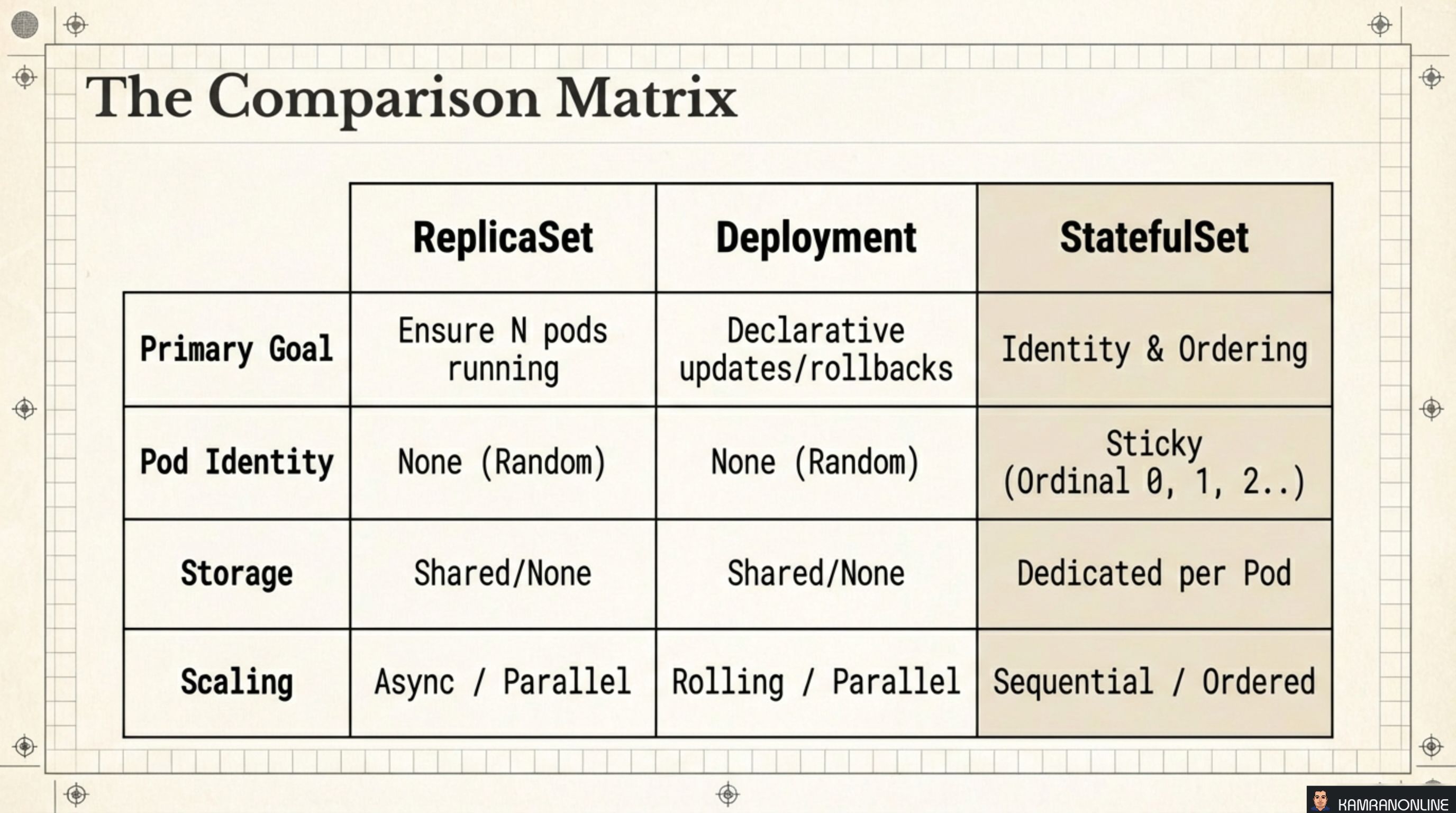
| ReplicaSet | Deployment | StatefulSet | |
|---|---|---|---|
| Primary Goal | Ensure N pods running | Declarative updates / rollbacks | Identity & ordering |
| Pod Identity | None (random) | None (random) | Sticky (ordinal 0, 1, 2…) |
| Storage | Shared / none | Shared / none | Dedicated per pod |
| Scaling | Async / parallel | Rolling / parallel | Sequential / ordered |
Selection Decision Tree
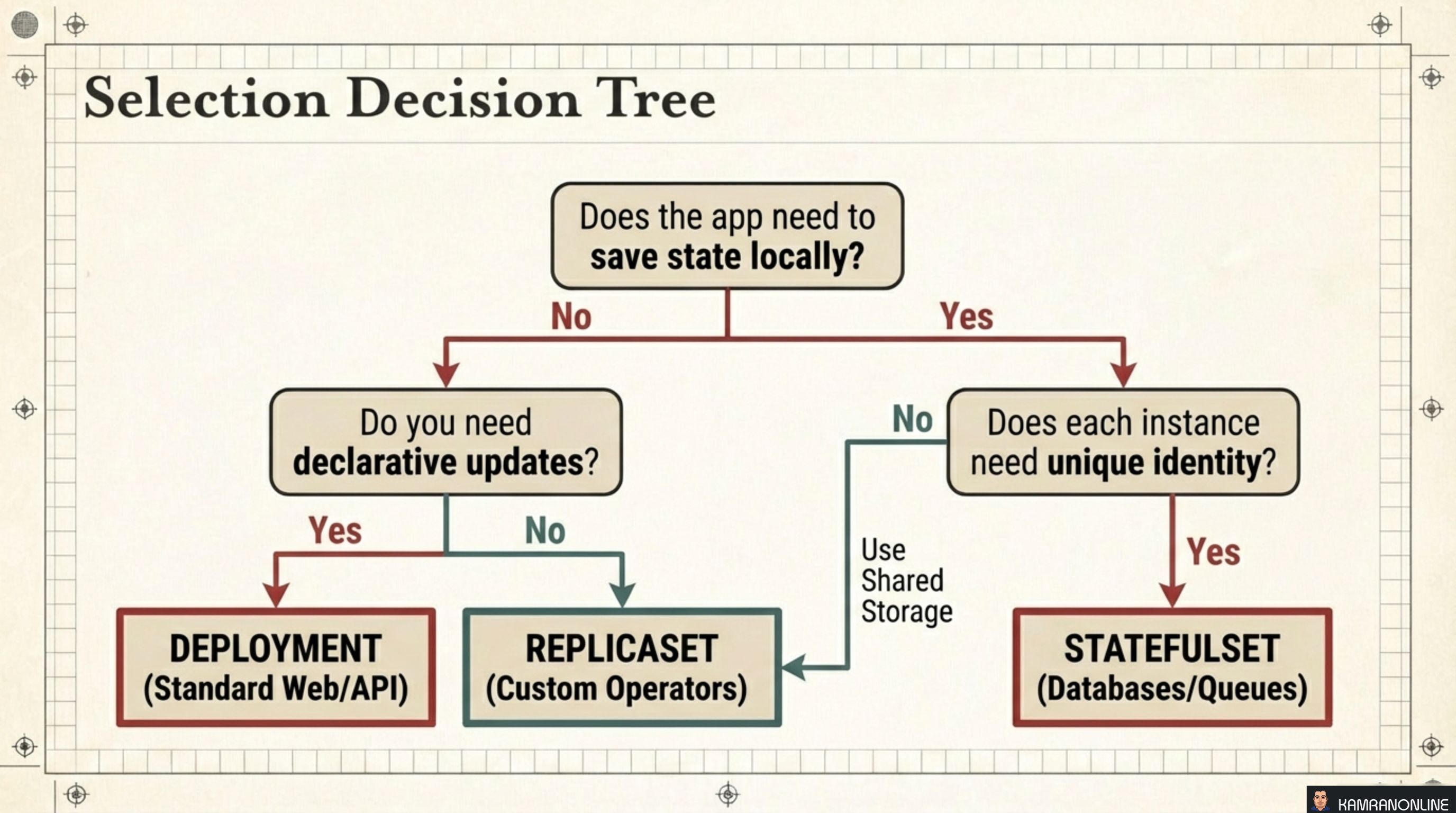
Use this flowchart when you’re writing a new manifest:
Does the app need to save state locally?
│
├─ No → Do you need declarative updates (rolling deploys, rollbacks)?
│ ├─ Yes → DEPLOYMENT (standard web apps, APIs, microservices)
│ └─ No → REPLICASET (custom operators managing their own update logic)
│
└─ Yes → Does each instance need a unique identity?
├─ No → Use shared storage + DEPLOYMENT
└─ Yes → STATEFULSET (databases, message queues, distributed systems)The vast majority of workloads land on Deployment. StatefulSet is reserved for the cases where the application itself has opinions about which instance is which.
Summary and Best Practices

Four rules to carry forward:
-
Default to Deployment. For stateless apps — microservices, APIs, web frontends — Deployment is always the right starting point. It handles updates, rollbacks, and scaling.
-
Avoid bare ReplicaSets. Always manage them via a Deployment. A bare ReplicaSet has no update strategy — you’d be back to manually deleting and recreating pods.
-
Use StatefulSet only for “pets”. If your application requires stable network identity and ordered deployment, StatefulSet is the right tool. If it doesn’t, the added complexity isn’t worth it.
-
Combine StatefulSets with Headless Services. A Headless Service (
clusterIP: None) gives each StatefulSet pod a stable DNS name (pod-0.svc.namespace.svc.cluster.local), enabling reliable peer discovery without a load balancer in front.
Kubernetes turns the tedious process of manually updating applications into a declarative activity.
The key insight that ties all three controllers together is the reconciliation loop. You declare intent; controllers continuously close the gap between that intent and reality. Whether it’s maintaining replica count, orchestrating a rolling update, or ensuring a database pod returns with its identity and storage intact — the mechanism is always the same loop: Observe, Analyze, Act.